07/06/2025 18:08:38
OpenAI kháng cáo lệnh giữ toàn bộ dữ liệu ChatGPT

Trong tháng trước, một thẩm phán liên bang đã ra phán quyết buộc OpenAI phải duy trì và lưu trữ toàn bộ dữ liệu từ ChatGPT, bao gồm cả những dữ liệu mà trước đây sẽ bị xóa theo chính sách quyền riêng tư của người dùng. Đây là động thái nằm trong khuôn khổ vụ kiện bản quyền giữa New York Times và OpenAI – vụ việc đang thu hút sự chú ý lớn trong giới công nghệ và pháp lý.
Từ năm 2023, New York Times đã đâm đơn kiện OpenAI và Microsoft, cáo buộc họ sử dụng trái phép nội dung bài báo để huấn luyện các mô hình AI như ChatGPT, vi phạm luật bản quyền. Phía OpenAI phản bác mạnh mẽ, cho rằng việc huấn luyện dựa trên dữ liệu công khai nằm trong phạm vi “sử dụng hợp lý” (fair use).
Tuy nhiên, đến tháng 5 vừa qua, New York Times và một số tổ chức truyền thông khác cáo buộc OpenAI đang "liên tục xóa bỏ" các bản ghi trò chuyện có thể là bằng chứng vi phạm bản quyền. Đáp lại, thẩm phán Ona Wang đã ra lệnh yêu cầu OpenAI giữ lại và tách biệt toàn bộ lịch sử trò chuyện ChatGPT, bất kể người dùng đã chọn xóa hay chưa.
Trong đơn kháng cáo, OpenAI khẳng định lệnh của tòa cản trở họ trong việc "tôn trọng lựa chọn quyền riêng tư của người dùng." Công ty cho biết họ chưa từng "hủy bỏ" dữ liệu một cách bất hợp pháp, và không xóa dữ liệu nào vì lý do liên quan đến vụ kiện.
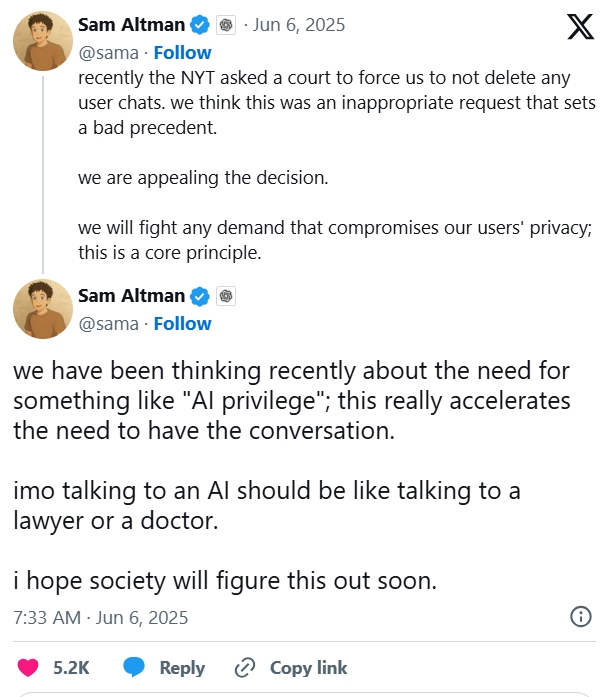
COO Brad Lightcap chỉ trích yêu cầu của tòa là "vô căn cứ" và "phủ nhận các chuẩn mực quyền riêng tư đã tồn tại lâu nay." Trong khi đó, CEO Sam Altman cũng lên tiếng trên mạng xã hội X (trước đây là Twitter), cho rằng yêu cầu này "tạo tiền lệ xấu" và nêu bật sự cần thiết phải xây dựng một "đặc quyền AI" – nơi giao tiếp với AI phải được bảo mật như khi nói chuyện với luật sư hay bác sĩ.
Sau phán quyết, nhiều người dùng trên mạng xã hội LinkedIn và X bày tỏ lo ngại. Một người viết rằng họ phải cảnh báo khách hàng “cẩn trọng hơn khi chia sẻ thông tin với ChatGPT.” Một người khác nhận định: “Wang nghĩ rằng mối lo ngại bản quyền của New York Times quan trọng hơn quyền riêng tư của toàn bộ người dùng OpenAI – thật điên rồ!”
Dù một số người không lo lắng về việc bị xem lịch sử chat, nhưng thực tế, nhiều người đã sử dụng ChatGPT như một chuyên gia tâm lý, cố vấn cuộc sống, thậm chí là “bạn tâm giao”. Và dù ai đó không dùng theo cách đó, họ vẫn có quyền giữ nội dung ấy ở chế độ riêng tư.
Tuy nhiên, cũng không thể phủ nhận rằng vụ kiện của New York Times mở ra cuộc tranh luận quan trọng về cách các công ty AI thu thập và sử dụng dữ liệu để huấn luyện. Các trường hợp như Clearview AI từng quét 30 tỷ hình ảnh từ Facebook để huấn luyện nhận diện khuôn mặt, hay chính phủ dùng ảnh của người yếu thế để thử nghiệm AI, cho thấy cần có ranh giới rõ ràng giữa quyền riêng tư và phát triển công nghệ.
Vấn đề cốt lõi đặt ra: Liệu các công ty như OpenAI có cần xin phép rõ ràng trước khi thu thập nội dung để huấn luyện AI, thay vì mặc nhiên lấy mọi thứ công khai trên Internet?


